About
Saft
… is a collection of lightweight components

Saft is the aim to build a collection of components which helps you to create applications by using Semantic Web/Linked Data technology. The main goal of Saft is to provide a full fledged middleware, which supports a wide range of use cases in the Semantic Web field, from data consuming, data manipulation, querying and database/store interaction. The project structure can be devided into saft.library, containing interfaces and components which can be included in any existing application structure, and the saft.skeleton, which helps developers to bootstrap an application from the scratch.
… is an integration platform
Saft is also an integration platform, which integrates foreign libraries and technologies, such as ARC2, EasyRdf or Redland, so you can use them together. They will be used, for instance, for parsing/serialization or triple store access. Saft handles the configuration and setup and appears as one API for the user. But he has the option to opt-in, if he wants.
Basic illustration
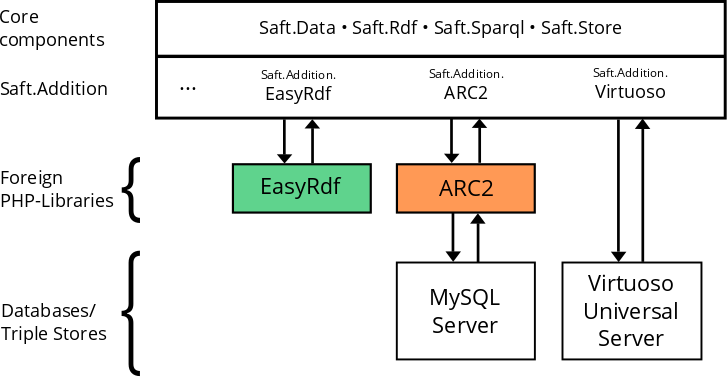
This image illustrates the integration platform. The core components provide basic functionality and interfaces. They build the basement for Saft.Addition, which contains real implementations, organized as components as well. Each addition has its own purpose.
For instance Saft.Addition.ARC2: It uses the foreign ARC2 library to provide a database adapter to use a MySQL database as triple store. To do so, it implements/extends existing classes and interfaces to connect with their ARC2 pendants.
… is compatible and open
One of the main goals of Saft is to be open and compatible. For instance:
- it is published under the terms of the GPL
- it supports PSR-7 for HTTP-handling (see REST API of Saft.skeleton)
- it embraces open standards, like the ones from the W3C or PHP-FIG (PHP Framework Interop Group)
- provides a public REST interface specification.
Saft is also open for participation and welcomes code, bug reports, translations, … any help from people, who want to help.
Motivation
There are already a couple of frameworks/libraries out there, providing support for RDF consumption and querying, build SPARQL etc. pp, so why we are doing this?
Basic use cases
Before we start to explain the reasons why Saft was developed and how it is in comparison to other projects, we want to discuss the use cases we want to cover.
1. Consuming RDF (load, manipulate, parse, serialize)
That is one of the main use-cases. RDF is a meta-data model and propagades the triple structure to store data. You can use RDF in the RDFa flavour to annotate your HTML and search engines like Google will recognize and use it. RDF is also a good way to interchange data.
Important tasks:
- Parse a file containing RDF data
- Store RDF data into a file
- Parse a string which contains RDF information
- Transform data into the RDF-format
2. Send and handle SPARQL queries
SPARQL is a mighty language and can be used as an interface to a service, application or library.
Important tasks:
- Build SPARQL queries using an API
- Send SPARQL to a local store or an endpoint on the internet
- Handle the result of a SPARQL result
3. Access triple and quad stores (even via emulation)
That use case is not Semantic Web specific, but very important for the data management though. Triple stores might provide interfaces for PDO or ODBC, but sometimes it is neccessary to use custom implementations to unleash the full potential of a database.
Important tasks:
- Provide an object oriented way to access a database (triple-/quadstore, RDBS)
- Provide an emulation to store non-relational data into a relational database. That comes in handy in combination with use case 4. integration into classic applications.
4. Integration into classic applications
Semantic Web technologies are (still) very cutting edge and not many folks know how to use it or what to use them for. So there must be an easy way to extend existing (legacy) applications using new Semantic Web technology. Furthermore tools must be provided to make it easy to use such technologies, without the need to study long specifications.
Important tasks:
- Provide easy-to-use tools (libraries, classes, even functions) for new users to use Semantic Web technologies inside his application
- Provide tools to to transform non-RDF data into the RDF format
- Support open standards and try to provide at least one working implementation, so the user is able to test and use it
Saft in comparison to existing projects
After we described the basic use cases, we think, are important to support, we will provide an overview about existing projects and what differenciates them from Saft. The following overview was made with that use cases in mind.
Erfurt Framework
The Erfurt framework was created by the ASKW and it is only be maintained currently, but there is no active development. It provides a good support for all important areas of the Semantic Web, from RDF consumption over building SPARQL-queries to extensive SPARQL query caching. The project owners of Saft were both working or still are on Erfurt. The main reason, why Saft was founded instead of helping Erfurt to claim new ground was because of Erfurts interal structure. It grows over time and there were some architectual choices made, which made it very hard to change something in the core. Furthermore, its test suite was abandoned and testing parts of Erfurt is very hard. Furthermore the lack of development from the original team was also a reason.
But Saft contains many ideas and even code from Erfurt. For instance, the Virtuoso Universal Server adapter from Erfurt is very handy. We dont see Saft as the successor of Erfurt, but Saft surely inherits some of Erfurts legacy. Erfurt is partly supported by Saft which means, that you can use Erfurts functionality inside of Saft. That enables you to use both, if you want.
EasyRdf
EasyRdf is a PHP library designed to make it easy to consume and produce RDF
It is very handy and provides a good set of components/functions and it is even part of Drupal 8 Core. But it lacks adapters to access triplestores and does not provide extensive SPARQL query handling. Because the founders previously worked on Erfurt, they had a certain opinion about the internal architecture of such a library.
Nevertheless, Saft provides an adapter for EasyRdf to provide its good parsing and serialization functionalities. As stated above, we designed Saft to be also an integration platform, integrating existing projects and provide a unified way to use them. We at Saft believe that you could always create your own project if want, if you are not satisfied with existing solution. But if you do so, you should also keep in mind, that existing solutions maybe way better than yours, so be as much compatible as possible, to provide a way for your users to use what they want and combine stuff without running into a dead end.
ARC2
ARC2 is a PHP 5.3 library for working with RDF. It also provides a MySQL-based triplestore with SPARQL support
ARC2 is a little bit like EasyRdf. For instance, it provides serialization and parsing components and an internal graph representation. It differs from EasyRDf by providing an adapter for the MySQL database to store triples (provides querying the data as well). It almost fully supports SPARQL 1.0 and some parts of SPARQL 1.1.
The project owner bnowack stated that there is no further development of ARC2:
Feature-wise, ARC2 is now in a stable state with no further feature additions planned. Issues are still being fixed and Pull Requests are welcome, though.
Not only that, adding support for SPARQL 1.1 would result into a lot of work on the internals (according issue). But despite that, Saft provides an adapter for ARC2, to use its good adapter for the MySQL database. Doing that, Saft is able to provide support for triple/quad data management in triple-/quadstores and relational databases. Well, currently ARC2 uses mysqli, but port it to ODBC via PDO should not that difficult.
So, why didn’t we supported ARC2? The reason was, its internal structure is not very OOP and the code is hard to understand. Furthermore implementing support for SPARQL 1.1 may result into rewriting (huge) parts of the library. Another reason is, that ARC2 does not seem to provide an abstraction layer to be independent from the underlying database adapter.
Nemrod (Symfony2)
Nemrod is a framework providing an abstraction layer for handling (consuming and producing) RDF in a Symfony2 project.
Well, that project came to our knowledge a few days ago (June 2015). Its documentation and code looked very promising, but it is tied to Symfony2. We wanted to create a project which is not specific to a certain use case/library/framework.
Short historical overview
The founders of Saft and SaftIng previously worked, some still are working, on Erfurt the PHP/Zend based Semantic Web Framework, which is the foundation e.g. for the collaborative Semantic software OntoWiki and the node for the Distributed Semantic Social Network Node xodx. k00ni created Enable in 2013/2014 during his study as a lightweight alternative to Erfurt. After half a year, he teamed up with the OntoWiki and Erfurt maintainer white_gecko and they decided to establish a fully fledged collection of components to build applications by using Semantic Web and Linked Data technology. They used their experience with Erfurt and code from Enable to start. These two were joined by vitaB, who mostly contributed code to the Store and REST components and by Oliver Skawronek, who layed the ground for a file based triple store.
What is SaftIng?
SaftIng stands for Semantic Application Framework Saft Engineering Taskforce (Saft.Ing), which is a group of developers with a strong background in Semantic Web and Linked Data technology.